E-KAR
Explainable & Knowledge-intensive Analogical Reasoning
👋 Hi, there! This is the project page for ACL 2022 (Findings) paper: “E-KAR: A Benchmark for Rationalizing Natural Language Analogical Reasoning”.
[News (09/2022)]: E-KAR v1.1 is officially released, with a higher-quality English dataset! In v1.1, we further improve the Chinese-to-English translation quality of the English E-KAR, with 600+ problems and 1,000+ explanations manually adjusted. You can still find the previous version (as in the paper) in the v1.0 branch in 🤗 datasets⬇️.

E-KAR Paper
Published in ACL 2022 (Findings) as Long Paper.

E-KAR Dataset (En)
English version (v1.1), hosted at 🤗 datasets

E-KAR Dataset (Zh)
Chinese version (v1.1), hosted at 🤗 datasets
About E-KAR
The ability to recognize analogies is fundamental to human cognition. Existing benchmarks to test word analogy do not reveal the underneath process of analogical reasoning of neural models.
Holding the belief that models capable of reasoning should be right for the right reasons, we propose a first-of-its-kind Explainable Knowledge-intensive Analogical Reasoning benchmark (E-KAR). Our benchmark consists of 1,655 (in Chinese) and 1,251 (in English) problems sourced from the Civil Service Exams, which require intensive background knowledge to solve. More importantly, we design a free-text explanation scheme to explain whether an analogy should be drawn, and manually annotate them for each and every question and candidate answer.
You can find the slides, poster and video about E-KAR at this website.
Data Instance
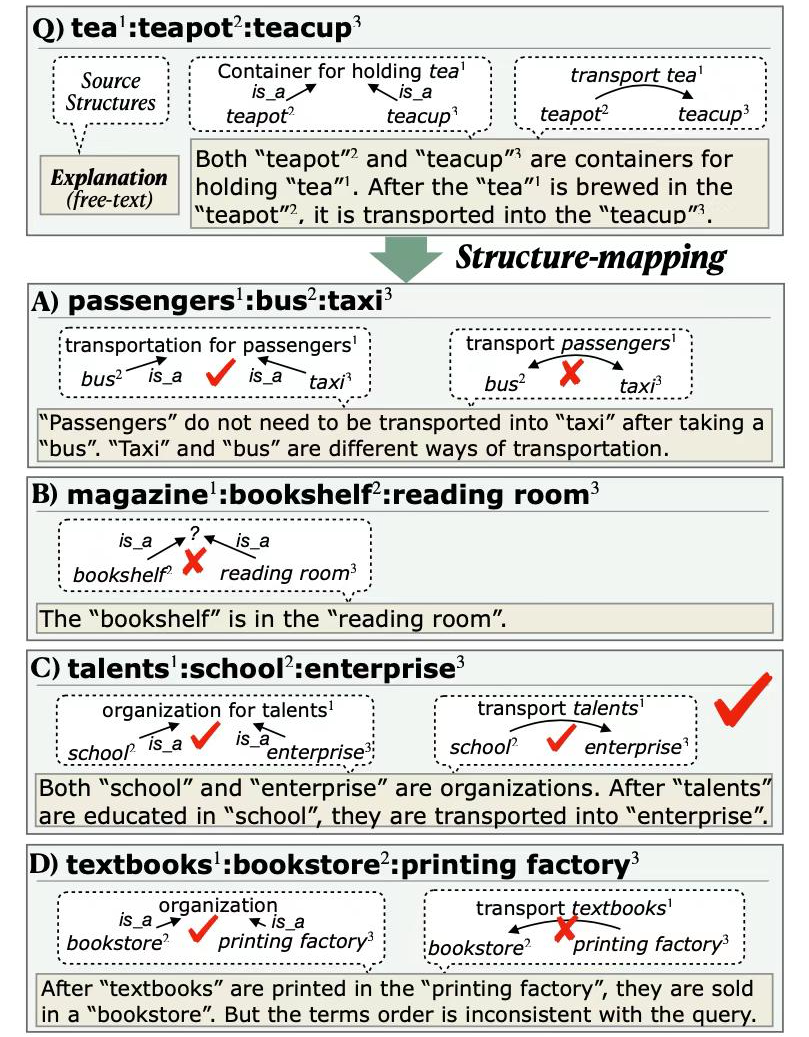
Query:
- tea: teapot: teacup
Candidate Answers:
A) passenger: bus: taxi
B) magazine: bookshelf: reading room
C) talents: school : enterprise
D) textbooks: bookstore: printing factory
Answer: C
Explanation for Query:
- $E_Q$: Both “teapot” and “teacup” are containers for holding “tea”. After the “tea” is brewed in the “teapot”, it is transported into the “teacup”.
Explanation for Candidate Answers:
$E_A$: “Passengers” do not need to be transported into “taxi” after taking a “bus”. “Taxi” and “bus” are different ways of transportation.
$E_B$: The “bookshelf” is in the “reading room”.
$E_C$: Both “school” and “enterprise” are organizations. After “talents” are educated in “school”, they are transported into “enterprise”.
$E_D$: After “textbooks” are printed in the “printing factory”, they are sold in a “bookstore”. But the terms order is inconsistent with the query.
How to Load the Dataset?
import datasets # 🤗
ekar_zh = datasets.load_dataset('Jiangjie/ekar_chinese')
ekar_en = datasets.load_dataset('Jiangjie/ekar_english')
Visualizing Analogical Reasoning
Shared Tasks in E-KAR
There are altogether 8 task settings: 2 shared tasks * 2 task modes * 2 languages.
E-KAR supports two shared tasks:
Analogical QA: The dataset can be used to train a model for analogical reasoning in the form of multiple-choice QA.Explanation Generation: The dataset can be used to generate free-text explanations to rationalize analogical reasoning.
E-KAR supports two task modes:
EASY mode: where query explanation ($E_Q$) can be used as part of the input.HARD mode: no explanation is allowed as part of the input.
E-KAR supports two languages:
Chinese version: 1,655 problems and 8,275 sentences of explanations, sourced from Civil Service Exams of China with manually annotated explanations.- Train split: 1155
- Validation split: 165
- Blind test split: 335
English version: 1,251 problems and 6,255 sentences of explanations, translated from Chinese version with culture-specific samples removed or rewritten.- Train split: 870
- Validation split: 119
- Blind test split: 262
Leaderboard
Please submit and evaluate your results on the test sets at the publicly available E-KAR leaderboard hosted at EvalAI.
Note that the leaderboard only evaluates Analogical QA and Rationalized Analogical QA tasks, in order to avoid using unreliable automatic metrics for evaluating text generation (i.e., explanations). See the E-KAR leaderboard for participation details.
Baseline Results
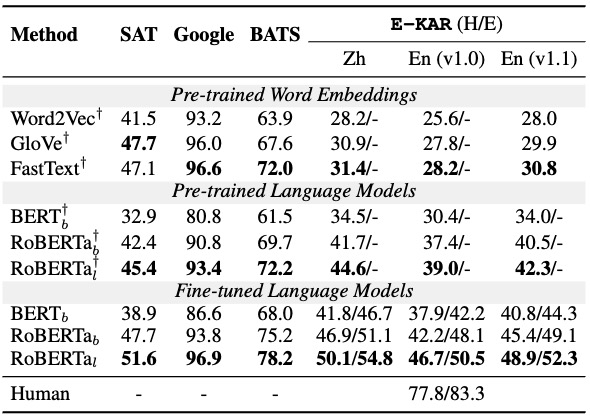
Table 1: Accuracy results on previous analogy tasks and the QA task in E-KAR (v1.0 -> v1.1). E-KAR (H/E) denotes HARD or EASY mode of analogical QA. Method† is not tuned. PLM-b or PLM-l denote base or large version, respectively.
Citation
If you find this work useful to your research, please kindly cite our paper:
@inproceedings{chen-etal-2022-e,
title = "{E}-{KAR}: A Benchmark for Rationalizing Natural Language Analogical Reasoning",
author = "Chen, Jiangjie and
Xu, Rui and
Fu, Ziquan and
Shi, Wei and
Li, Zhongqiao and
Zhang, Xinbo and
Sun, Changzhi and
Li, Lei and
Xiao, Yanghua and
Zhou, Hao",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2022",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-acl.311",
pages = "3941--3955",
}
Acknowledgements
This work is supported by the following organizations: